


Predictive analytics and artificial intelligence (AI) are revolutionizing data-driven decision making in businesses. With the advent of sophisticated machine learning algorithms and AI technologies, organizations are now able to leverage the power of predictive analytics to gain valuable insights, forecast trends, and make informed decisions that drive success.
In predictive analytics, data models and machine learning algorithms are used to analyze vast amounts of data and identify patterns that can be used to make accurate predictions about future events. By harnessing the capabilities of AI, businesses can quickly and accurately analyze large data sets, enabling them to identify trends and make strategic decisions that optimize processes such as supply chain management and marketing campaigns.
By utilizing AI in predictive analytics, businesses can unlock the full potential of their data and gain a competitive edge in the market. AI enables machines to perform tasks that would otherwise require human intelligence, such as processing and analyzing massive amounts of data rapidly. This allows businesses to make data-driven decisions in real-time, anticipating market changes, and adjusting strategies accordingly.

Understanding Predictive Analytics
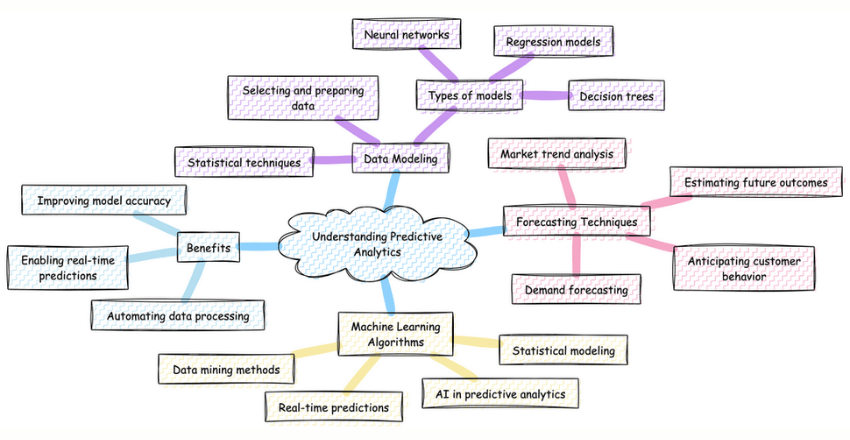
Predictive analytics involves the use of data models, forecasting techniques, and machine learning algorithms to make accurate predictions about future events. By analyzing historical data, predictive models can identify patterns and trends that help businesses anticipate market changes, optimize processes, and make informed decisions. This powerful analytical approach is transforming the way businesses operate, allowing them to stay ahead of the competition and drive success.
One of the key components of predictive analytics is data modeling. This process involves selecting and preparing the relevant data to create a model that can make accurate predictions. Data models can take various forms, such as regression models, decision trees, or neural networks. These models use statistical techniques to analyze data and uncover relationships between variables, enabling businesses to make predictions based on historical patterns.
Forecasting techniques play a crucial role in predictive analytics. These techniques use historical data to estimate future outcomes and trends. Businesses can leverage forecasting to anticipate customer behavior, demand for products or services, and market trends, allowing them to make proactive decisions and adjust strategies accordingly.
Predictive analytics leverages AI to forecast future outcomes based on historical and real-time data. This involves using statistical modeling, data mining methods, and machine learning algorithms to analyze data and make predictions.
AI enhances predictive analytics by automating data processing, improving model accuracy, and enabling real-time predictions.
Examples of AI in Predictive Analytics Insurance
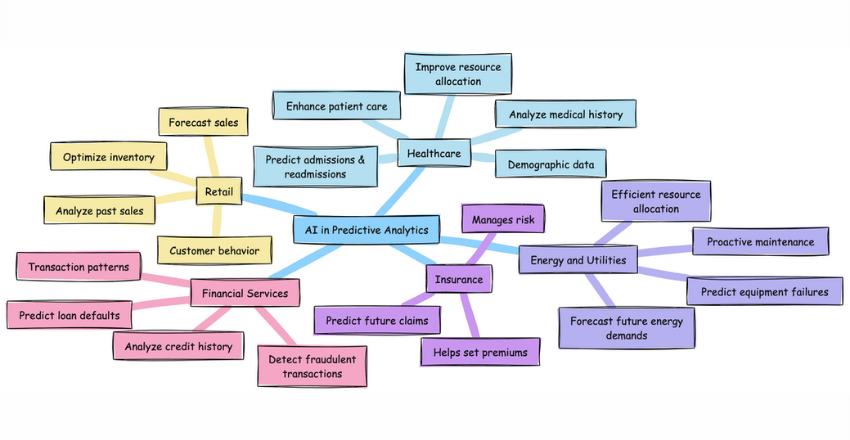
AI models can predict the likelihood of future claims by analyzing policyholder data, helping insurers set premiums and manage risk .
Financial Services: AI can predict loan defaults and detect fraudulent transactions by analyzing credit history and transaction patterns .
Retail: Retailers use AI to forecast sales and optimize inventory by analyzing past sales data and customer behavior .
Healthcare: AI models predict patient admissions and readmissions by analyzing medical history and demographic data, improving resource allocation and patient care .
Energy and Utilities: AI predicts equipment failures and future energy demands, enabling proactive maintenance and efficient resource allocation .
Common Predictive Analytics Models Classification Model: Categorizes data based on historical data to answer yes/no questions, such as predicting customer churn or loan approval .
Clustering Model: Groups data into clusters based on similar attributes, useful for targeted marketing and customer segmentation .
Forecast Model: Predicts numeric values based on historical data, such as sales forecasts or call center volume predictions .
Outliers Model: Identifies anomalous data points, useful for fraud detection and identifying unusual patterns .
Time Series Model: Analyzes data points over time to predict future values, such as sales trends or patient visits .
Code Samples for Predictive Analytics Below is a Python example using the scikit-learn library to create a simple predictive model. This example uses a classification model to predict whether a customer will churn based on historical data.
Pseudocode
- Import necessary libraries.
- Load and preprocess the dataset.
- Split the dataset into training and testing sets.
- Train a classification model (e.g., Random Forest).
- Evaluate the model’s performance.
- Make predictions on new data.
Python Code
Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
Load the dataset
data = pd.read_csv('customer_churn.csv')
Preprocess the dataset (example: handle missing values, encode categorical variables)
data.fillna(method='ffill', inplace=True)
data = pd.get_dummies(data, drop_first=True)
Split the dataset into features and target variable
X = data.drop('churn', axis=1)
y = data['churn']
Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train a Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Make predictions on the test set
y_pred = model.predict(X_test)
Evaluate the model's performance
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Classification Report:')
print(report)
Make predictions on new data
new_data = pd.DataFrame({
'feature1': [value1],
'feature2': [value2],
# Add other features as required
})
new_data = pd.get_dummies(new_data, drop_first=True)
prediction = model.predict(new_data)
print(f'Prediction: {prediction}')Real-Time Predictions in Predictive Analytics
Benefits for Businesses:
Real-time predictions allow businesses to make immediate, data-driven decisions. For example, in e-commerce, real-time predictions can help in dynamic pricing, inventory management, and personalized marketing. In finance, they can detect fraudulent transactions as they occur, minimizing losses.
Code Sample:
Below is an example using Python and the scikit-learn library to make real-time predictions. This example uses a pre-trained model to predict whether a transaction is fraudulent in real-time.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import joblib
Load pre-trained model
model = joblib.load('fraud_detection_model.pkl')
Example real-time transaction data
real_time_data = pd.DataFrame({
'feature1': [value1],
'feature2': [value2],
Add other features as required
})
Make real-time prediction
prediction = model.predict(real_time_data)
print(f'Real-time Prediction: {prediction}')AI in Predictive Analytics and Data Processing Efficiency
Improvement in Data Processing Efficiency:
AI improves data processing efficiency by automating data cleaning, feature selection, and model training. This reduces the time and effort required to prepare data and build models, allowing businesses to focus on interpreting results and making decisions.
Code Sample:
Using Python and pandas for data preprocessing and scikit-learn for model training:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
Load dataset
data = pd.read_csv('data.csv')
Automated data cleaning
data.fillna(method='ffill', inplace=True)
Feature selection (example: selecting top 5 features based on correlation)
correlation = data.corr()
top_features = correlation['target'].abs().sort_values(ascending=False).index[1:6]
X = data[top_features]
y = data['target']
Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Evaluate model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')Role of Machine Learning Algorithms in Predictive Analytics
Explanation:
Machine learning algorithms are the backbone of predictive analytics. They learn patterns from historical data and use these patterns to make predictions on new data. Common algorithms include linear regression, decision trees, and neural networks.
Code Sample:
Using a Decision Tree Classifier to predict customer churn:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
Load dataset
data = pd.read_csv('customer_churn.csv')
Preprocess data
data.fillna(method='ffill', inplace=True)
data = pd.get_dummies(data, drop_first=True)
Split data
X = data.drop('churn', axis=1)
y = data['churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train Decision Tree Classifier
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
Evaluate model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')Common Challenges in Implementing AI in Predictive Analytics
Challenges:
- Data Quality: Incomplete or noisy data can lead to inaccurate predictions.
- Model Complexity: Complex models can be difficult to interpret and require significant computational resources.
- Integration: Integrating AI models into existing systems can be challenging.
- Scalability: Ensuring that models can handle large volumes of data in real-time.
Code Sample:
Handling missing data and scaling the model:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
Load dataset
data = pd.read_csv('data.csv')
Handle missing data
data.fillna(method='ffill', inplace=True)
Feature scaling
scaler = StandardScaler()
scaled_features = scaler.fit_transform(data.drop('target', axis=1))
Split data
X = pd.DataFrame(scaled_features, columns=data.columns[:-1])
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
Evaluate model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')These examples illustrate how AI and machine learning can be applied to predictive analytics, improving data processing efficiency, making real-time predictions, and addressing common challenges.
Source Links
https://intellectdata.com/ai-driven-predictive-analytics/
https://www.unifyr.ai/blog-2/the-future-of-data-driven-decision-making-predictive-analytics-and-ai








 We use cookies to ensure that we give you the best experience on our website and show you relevant advertising. If you continue to use this site we will assume that you are happy with it. To find out more read our
We use cookies to ensure that we give you the best experience on our website and show you relevant advertising. If you continue to use this site we will assume that you are happy with it. To find out more read our